Distributed Training
Distributed training is a technique that allows you to train your pipeline on multiple workers/machines. This is useful when you have a large model or computation graph that doesn’t fit on a single GPU/machine, or when you want to train a model faster by using more resources.
TorchOpt offers a simple API to train your model on multiple GPUs/machines based on the PyTorch Distributed RPC Framework (torch.distributed.rpc).
Here are some key concepts that TorchOpt’s distributed mechanism relies on:
Remote Procedure Call (RPC) supports running a function on the specified destination worker with the given arguments and getting the return value back or creating a reference to the return value.
That is, you can treat the remote worker as an accelerator. You can call a function on a remote worker and get the result back to the local worker.
Distributed Autograd stitches together local autograd engines on all the workers involved in the forward pass, and automatically reach out to them during the backward pass to compute gradients.
This is much more flexible to fit the meta-learning use case to have a complex task dependency tree.
Here are some useful resources to learn more about distributed training:
Why RPC-Based Distributed Training
Due to the Global Interpreter Lock (GIL) in Python, only one thread can execute Python code at a time. This means that you can’t take advantage of multiple cores on your machine. Distribute the workload across multiple processes, or namely workers, that will run in parallel to gain faster execution performance. Each worker will have its own Python interpreter and memory namespace.
Compare to single-process programming, you need to be aware of the following:
Communication: You need to explicitly send and receive messages between workers.
Synchronization: You need to explicitly synchronize the states between workers.
Message Passing Interface (MPI) and Distributed Data-Parallel Training (DDP)
MPI is a standard for message passing between processes. It is a popular choice for Distributed Data-Parallel Training (DDP). PyTorch has implemented this with several backends, including Gloo, MPI, and NCCL.
However, MPI-based parallelism has some drawbacks:
MPI is not user-friendly. MPI-like APIs only provide low-level primitives for sending and receiving messages. It requires the users to manage the message passing between workers manually. The users should be aware of the communication pattern and the synchronization between workers.
MPI is not flexible. MPI-like APIs are designed for Distributed Data-Parallel Training (DDP), which is a widely adopted single-program multiple-data (SPMD) training paradigm. However, for meta-learning tasks, the task dependency tree is complex and dynamic. It may not fit into the SPMD paradigm. It is hard to implement the distributed autograd engine on top of MPI.
MPI only communicates the value of tensors but not the gradients and graphs. This is a limitation of MPI. The users need to handle the gradients manually across multiple workers. For example, receive the gradients from other workers and put them as
grad_outputsto functiontorch.autograd.grad.
Distributed Autograd with Remote Procedure Call (RPC)
To address the needs of meta-learning tasks, which have complex and dynamic nature of the training process.
TorchOpt uses PyTorch Distributed RPC Framework (torch.distributed.rpc) to implement the distributed training mechanism.
PyTorch implements the RPC communication operations with appropriate RpcSendBackward and RpcRecvBackward functions.
The Distributed Autograd Engine automatically calls these functions to send and receive the gradients between workers.
With RPC and Distributed Autograd, TorchOpt distributes a differentiable optimization job across multiple workers and executes the workers in parallel. It allows the users to build the whole computation graph (both forward and backward) across multiple workers. The users can wrap code in the distributed autograd module and achieve substantial speedup in training time with only a few changes in existing training scripts. (example)
Here is an example of distributed autograd graph using RPC from Distributed Backward Pass documentation:
import torch
import torch.distributed.autograd as dist_autograd
import torch.distributed.rpc as rpc
def my_add(t1, t2):
return torch.add(t1, t2)
# On worker 0:
# Setup the autograd context. Computations that take
# part in the distributed backward pass must be within
# the distributed autograd context manager.
with dist_autograd.context() as context_id:
t1 = torch.rand((3, 3), requires_grad=True)
t2 = torch.rand((3, 3), requires_grad=True)
# Perform some computation remotely.
t3 = rpc.rpc_sync("worker1", my_add, args=(t1, t2))
# Perform some computation locally based on the remote result.
t4 = torch.rand((3, 3), requires_grad=True)
t5 = torch.mul(t3, t4)
# Compute some loss.
loss = t5.sum()
# Run the backward pass.
dist_autograd.backward(context_id, [loss])
# Retrieve the gradients from the context.
dist_autograd.get_gradients(context_id)
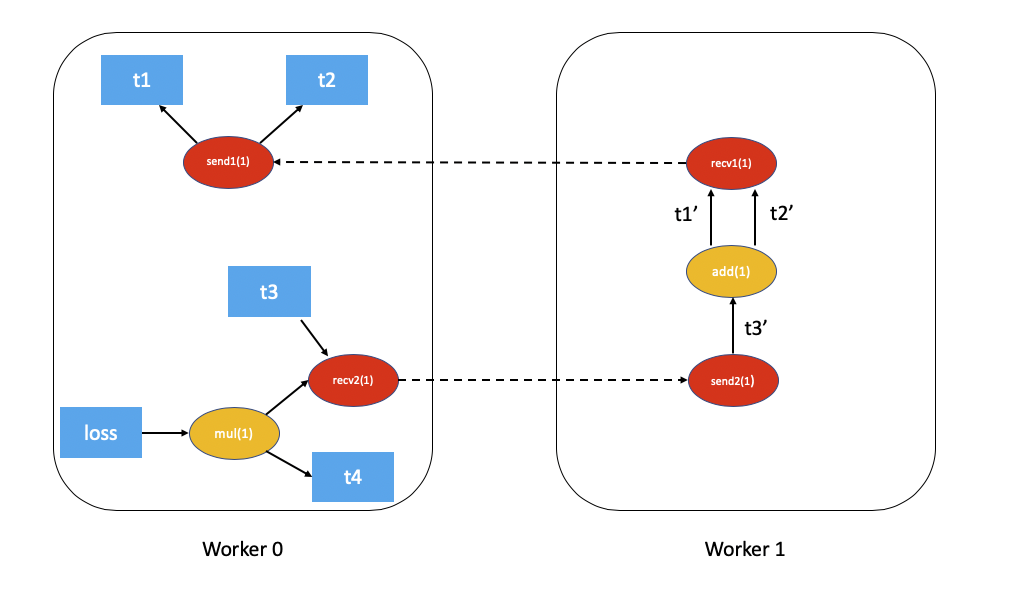
For more details, please refer to the Distributed Autograd Design documentation.
TorchOpt’s Distributed Training
TorchOpt’s distributed package is built upon the PyTorch Distributed RPC Framework (torch.distributed.rpc) and Distributed Autograd Framework (torch.distributed.autograd).
TorchOpt provides some utility functions to make it easier to use the distributed training mechanism.
Initialization and Synchronization
Return a decorator to automatically initialize RPC on the decorated function. |
|
|
Synchronize local and remote RPC processes. |
Users can wrap their program entry function with the decorator torchopt.distributed.auto_init_rpc():
import torchopt.distributed as todist
def parse_arguments():
parser = argparse.ArgumentParser()
...
return args
def worker_init_fn():
# set process title, seeding, etc.
...
@todist.auto_init_rpc(worker_init_fn)
def main():
# Your code here
args = parse_arguments()
...
if __name__ == '__main__':
main()
The decorator will initialize the RPC framework and synchronize the workers on startup.
Note
By default, all tensors must move to the CPU before sending them to other workers.
If you want to send/receive the tensors directly between GPUs from different workers, you need to specify the rpc_backend_options with device_maps.
Please refer to the documentation of torch.distributed.rpc.init_rpc for more details.
Then, users can use torchrun (Elastic Launch) to launch the program:
torchrun --nnodes=1 --nproc_per_node=8 YOUR_TRAINING_SCRIPT.py (--arg1 ... train script args...)
Process group information
Get the world information. |
|
Get the global world rank of the current worker. |
|
Get the global world rank of the current worker. |
|
Get the world size. |
|
Get the local rank of the current worker on the current node. |
|
Get the local world size on the current node. |
|
Get the worker id from the given id. |
After initializing the RPC server, users can use the above functions to get the process group information.
For example, use torchopt.distributed.get_local_rank() to determine which GPU device to use:
import torch
import torchopt.distributed as todist
def worker_init_fn():
local_rank = todist.get_local_rank()
torch.cuda.set_device(local_rank)
@todist.auto_init_rpc(worker_init_fn)
def main():
...
Worker selection
|
Return a decorator to mark a function to be executed only on given ranks. |
|
Return a decorator to mark a function to be executed only on non given ranks. |
Return a decorator to mark a function to be executed only on rank zero. |
|
Return a decorator to mark a function to be executed only on non rank zero. |
TorchOpt provides some decorators to execute the decorated function on specific workers.
For example, use torchopt.distributed.rank_zero_only() to execute the function only on the main worker (worker0), such as saving checkpoints or logging the results:
import torchopt.distributed as todist
@todist.rank_non_zero_only
def greet():
print(f'Greetings from worker(rank={todist.get_rank()})!')
@todist.rank_zero_only
def save_checkpoint(model):
...
@todist.rank_zero_only
def log_results(writer, results):
...
@todist.auto_init_rpc()
def main():
greet()
...
for epoch in range(args.epochs):
...
if epoch % args.log_interval == 0:
log_results(writer, results)
if epoch % args.save_interval == 0:
save_checkpoint(model)
Remote Procedure Call (RPC)
Asynchronously do an RPC on remote workers and return the a |
|
Do an RPC synchronously on remote workers and return the result to the current worker. |
TorchOpt provides two functions to execute the remote procedure call (RPC) on remote workers.
The asynchronous version remote_async_call() function returns a torch.Future object, and the remote_sync_call() function executes and returns the result directly.
Users can distribute their workload (a function) to a specific worker by:
import torchopt.distributed as todist
@todist.auto_init_rpc(worker_init_fn)
def main():
...
# Execute the function on the remote worker (asynchronously)
future = todist.remote_async_call(
func,
args=(arg1, arg2, ...),
kwargs={...},
partitioner=worker_id,
)
# Wait for the result
result = future.wait()
...
or
import torchopt.distributed as todist
@todist.auto_init_rpc(worker_init_fn)
def main():
...
# Execute the function on the remote worker
result = todist.remote_sync_call(
func,
args=(arg1, arg2, ...),
kwargs={...},
partitioner=worker_id,
)
...
TorchOpt follows the MapReduce programming model to distribute the workload.
The partitioner argument specifies the worker to execute the function.
The users can optionally specify the reducer argument to aggregate the results from the workers.
Finally, the caller will get a reference to the result on the local worker.
partitioner: a function that takes theargsandkwargsarguments and returns a list of triplets(worker_id, worker_args, worker_kwargs).The
partitioneris responsible for partitioning the workload (inputs) and distributing them to the remote workers.If the
partitioneris given by a worker ID (intorstr), the function will be executed on the specified worker.If the
partitioneris not given, thetorchopt.distributed.batch_partitioner()will be used.mapper: thefuncargument to be executed on the remote worker.reducer(optional): aggregation function, takes a list of results from the remote workers and returns the final result.If the
reduceris not given, returns the original unaggregated list.
Predefined partitioners and reducers
|
Partition a batch of inputs along a given dimension. |
Partitioner class that partitions a batch of inputs along a given dimension. |
|
|
Reduce the results by averaging them. |
|
Reduce the results by summing them. |
We provide some predefined partitioners and reducers.
Users can combine the torchopt.distributed.batch_partitioner() and torchopt.distributed.mean_reducer() to achieve the distributed data parallelism (DDP) easily:
import torchopt.distributed as todist
def loss_fn(model, batch):
...
@todist.rank_zero_only
def train(args):
for epoch in range(args.epochs):
...
for batch in dataloader:
# Partition the data on the batch (first) dimension and distribute them to the remote workers
# Aggregate the results from the remote workers and return the mean loss
loss = todist.remote_sync_call(
loss_fn,
args=(model, batch),
partitioner=todist.batch_partitioner,
reducer=todist.mean_reducer,
)
...
We also provide a torchopt.distributed.dim_partitioner() to partition the data on the specified dimension.
While implementing the Model-Agnostic Meta-Learning (MAML) [FAL17] algorithm, users can use this to parallel the training for the inner loop:
import torchopt.distributed as todist
def inner_loop(model, task_batch, args):
# task_batch: shape = (B, *)
inner_model = torchopt.module_clone(model, by='reference', detach_buffers=True)
# Inner optimization
for inner_step in range(args.inner_steps):
inner_loss = inner_loss_fn(inner_model, task_batch)
# Update the inner model
...
# Compute the outer loss
outer_loss = inner_loss_fn(inner_model, task_batch)
return outer_loss
@todist.rank_zero_only
def train(args):
for epoch in range(args.epochs):
...
for batch in dataloader:
# batch: shape = (T, B, *)
outer_loss = todist.remote_sync_call(
inner_loop,
args=(model, batch),
partitioner=todist.dim_partitioner(0, exclusive=True, keepdim=False),
reducer=todist.mean_reducer,
)
...
The dim_partitioner(0, exclusive=True, keepdim=False) will split the batch of size (T, B, *) into T batches of size (B, *).
Each task will be executed on the remote worker independently (exclusive=True).
Finally, the results will be aggregated by the torchopt.distributed.mean_reducer() to compute the mean loss.
Inside the inner_loop function, users may use another RPC call to further parallelize the inner loop optimization.
Function parallelization wrappers
Return a decorator for parallelizing a function. |
|
Return a decorator for parallelizing a function. |
|
Return a decorator for parallelizing a function. |
TorchOpt offers wrappers to parallelize the function execution on the remote workers. It makes the function execution on the remote workers more transparent to the users and makes the code structure clear.
import torchopt.distributed as todist
@todist.parallelize(partitioner=todist.batch_partitioner, reducer=todist.mean_reducer)
def distributed_data_parallelism(model, batch, args):
# Compute local loss of the given batch
...
return loss
@todist.parallelize(
partitioner=todist.dim_partitioner(0, exclusive=True, keepdim=False),
reducer=todist.mean_reducer,
)
def inner_loop(model, batch, args): # distributed MAML inner loop
# batch: shape = (B, *)
inner_model = torchopt.module_clone(model, by='reference', detach_buffers=True)
# Inner optimization
...
# Compute the outer loss
outer_loss = inner_loss_fn(inner_model, task_batch)
return outer_loss
@todist.rank_zero_only
def train(args):
for epoch in range(args.epochs):
...
for batch in dataloader:
# batch: shape = (T, B, *)
outer_loss = inner_loop(model, batch, args)
...
Distributed Autograd
Context object to wrap forward and backward passes when using distributed autograd. |
|
Retrieves a map from Tensor to the appropriate gradient for that Tensor accumulated in the provided context corresponding to the given |
|
Perform distributed backward pass for local parameters. |
|
|
Compute and return the sum of gradients of outputs with respect to the inputs. |
In this section, we will introduce the distributed autograd system. Please refer to Autograd mechanics and Distributed Autograd Design first before going through this section.
Recap: Autograd mechanics in single-process training
In single-process training, the autograd engine will automatically track the operations on the forward pass and compute the gradients on the backward pass.
For each operation, if the input tensors have requires_grad=True set, the output tensor will have a grad_fn attribute to trace the computation graph.
On the backward pass, the autograd engine will traverse the computation graph from the output tensors to the input tensors and compute the gradients for each operation.
The torch.autograd.grad function will compute the gradients of the given outputs with respect to the given inputs.
import torch
model = build_model()
loss = compute_loss(model, data)
params = tuple(model.parameters())
grads = torch.autograd.grad(loss, params)
print(grads)
In practice, users usually use the PyTorch Autograd Engine with loss.backward() (or torch.autograd.backward) and optimizers:
import torch
import torch.optim as optim
model = build_model()
optimizer = optim.SGD(model.parameters(), lr=lr)
loss = compute_loss(model, data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Compare to torch.autograd.grad, the torch.autograd.backward function will sum and update the .grad attribute of the parameters.
RPC-based Distributed Autograd
PyTorch RPC framework implements the communication send-recv operations with appropriate backward functions (RpcSendBackward and RpcRecvBackward).
They can be tracked by the Distributed Autograd Engine like the single-process program we discussed above.
The only difference between the single-process and distributed training is that users need to explicitly create a Distributed Autograd Context and wrap around the forward and backward passes.
import torch
import torch.distributed.autograd as dist_autograd
with dist_autograd.context() as context_id:
# Forward pass
loss = ... # e.g. remote calls
# Backward pass
dist_autograd.backward(context_id, [loss])
# Retrieve the gradients from the context.
grad_dict = dist_autograd.get_gradients(context_id) # type: Dict[Tensor, Tensor]
Warning
Sending torch.nn.Parameters over RPC will automatically detach from the autograd graph.
This is an intentional behavior of the PyTorch framework because the torch.nn.Parameters are always leaf nodes in the graph.
The leaf tensors will not have grad_fn attribute and thus cannot be tracked by the autograd engine after sending them to other workers.
To make the graph can be properly tracked across workers, users should convert the torch.nn.Parameters to torch.Tensors before sending them over RPC.
For example, explicitly clone() the parameters to tensors before taking them as arguments of the RPC call.
import torch
import torch.distributed.rpc as rpc
def compute_loss(param):
return param.mean()
param = torch.nn.Parameter(torch.randn(2, 2), requires_grad=True)
# The RPC call will detach the parameter from the autograd graph on worker1
loss1 = rpc.rpc_sync('worker1', compute_loss, args=(param,))
# The RPC call will keep connection to the parameter in the autograd graph on worker1
loss2 = rpc.rpc_sync('worker1', compute_loss, args=(param.clone(),))
Users can use torchopt.module_clone() function to clone the module and convert all its parameters to tensors.
The tensors will have a grad_fn attribute CloneBackward to track the computation graph to the original parameters.
import torch
import torch.nn as nn
import torchopt
def compute_loss(model, batch):
...
return loss
model = nn.Linear(2, 2)
tuple(model.parameters()) # -> `nn.Parameter`s
cloned_model = torchopt.module_clone(model, by='clone')
tuple(cloned_model.parameters()) # -> `torch.Tensor`s with `CloneBackward` grad_fn
# The RPC call will detach the parameter from the autograd graph on worker1
loss1 = rpc.rpc_sync('worker1', compute_loss, args=(model, batch))
# The RPC call will keep the connection to the parameter in the autograd graph on worker1
loss2 = rpc.rpc_sync('worker1', compute_loss, args=(cloned_model, batch))
TorchOpt wraps the distributed autograd context and provides a more convenient interface to use.
import torchopt.distributed as todist
model = build_model()
with todist.autograd.context() as context_id:
# Forward pass
loss = ... # e.g. remote calls
# Backward pass
grads = todist.autograd.grad(context_id, loss, model.parameters())
or
import torch
import torchopt.distributed as todist
model = build_model()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
with todist.autograd.context() as context_id:
# Forward pass
loss = ... # e.g. remote calls
# Backward pass
optimizer.zero_grad()
todist.autograd.backward(context_id, loss)
optimizer.step()
Warning
The distributed autograd context is not thread-safe. Users should not use the same context in multiple threads.
Users can update their single-process training code to distributed training code with minimum changes:
Add the distributed autograd context around the forward and backward passes.
Wrap the functions with
torchopt.distributed.parallelize()to enable parallel execution.Convert the parameters to tensors before sending them over RPC.
Replace the
torch.autogradtotorchopt.distributed.autograd.
Here is a full example of converting the single-process training code to distributed training code:
import torch
import torch.nn as nn
import torchopt.distributed as todist
def parse_arguments():
parser = argparse.ArgumentParser(description='TorchOpt Distributed Training')
...
args = parser.parse_args()
return args
def worker_init_fn():
# set process title, seeding, etc.
setproctitle.setproctitle(f'Worker{todist.get_rank()}')
torch.manual_seed(args.seed + todist.get_rank())
@todist.parallelize(partitioner=todist.batch_partitioner, reducer=todist.mean_reducer)
def compute_loss(model, batch):
device = torch.device(f'cuda:{todist.get_local_rank()}')
model = model.to(device)
batch = batch.to(device)
# Compute local loss of the given batch
...
return loss.cpu()
def build_model():
return nn.Sequential(
...
)
@todist.rank_zero_only
def train(args):
model = build_model()
optimizer = torch.optim.SGD(model.parameters(), lr=args.lr)
train_loader = ...
for epoch in range(args.epochs):
for batch in train_loader:
with todist.autograd.context() as context_id:
# Forward pass
cloned_model = todist.module_clone(model, by='clone')
loss = compute_loss(cloned_model, batch)
# Backward pass
optimizer.zero_grad()
todist.autograd.backward(context_id, loss)
# Update parameters
optimizer.step()
@todist.auto_init_rpc(worker_init_fn)
def main():
args = parse_arguments()
train(args)
if __name__ == '__main__':
main()
Then, users can use torchrun (Elastic Launch) to launch the program:
torchrun --nnodes=1 --nproc_per_node=8 YOUR_TRAINING_SCRIPT.py (--arg1 ... train script args...)